


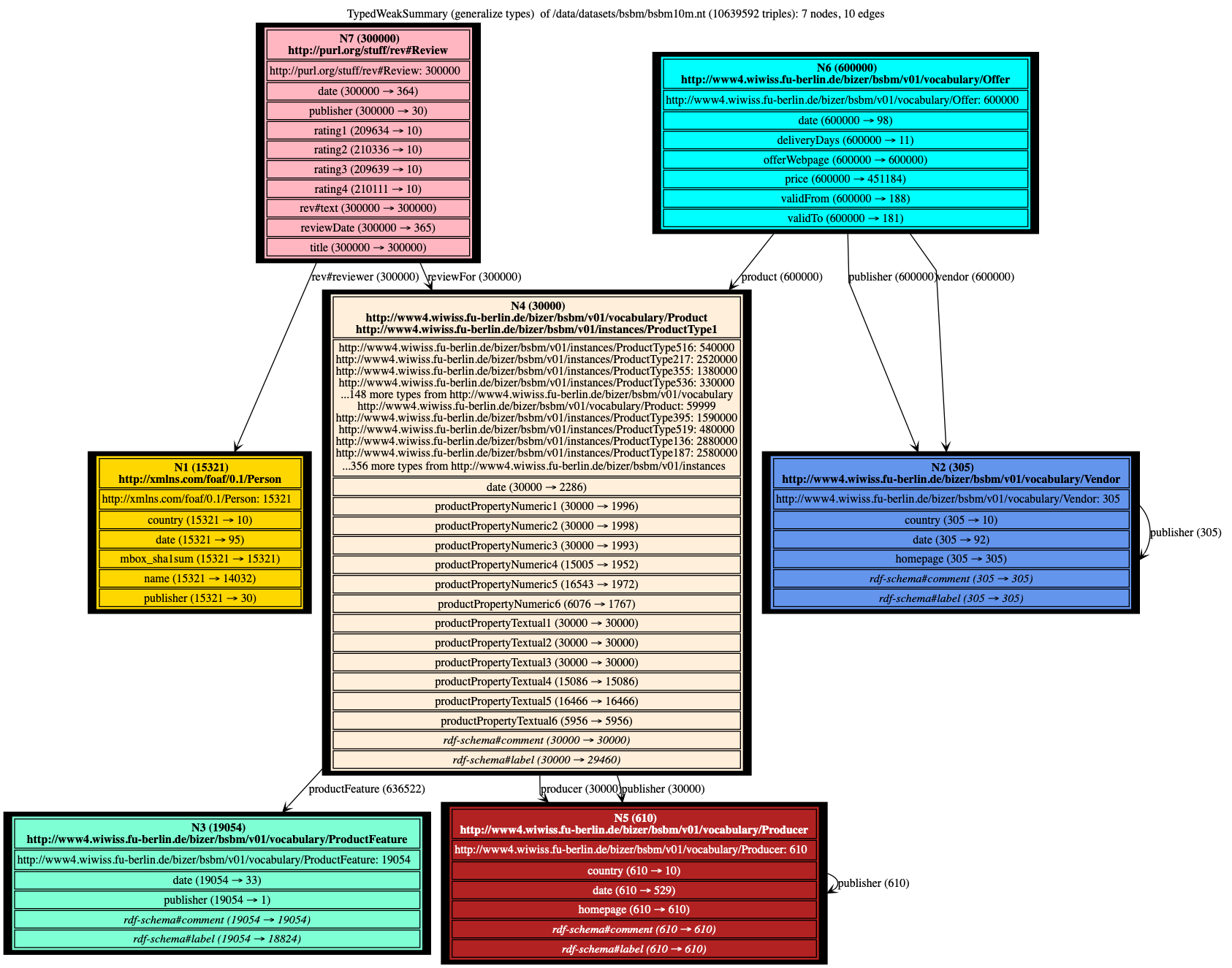
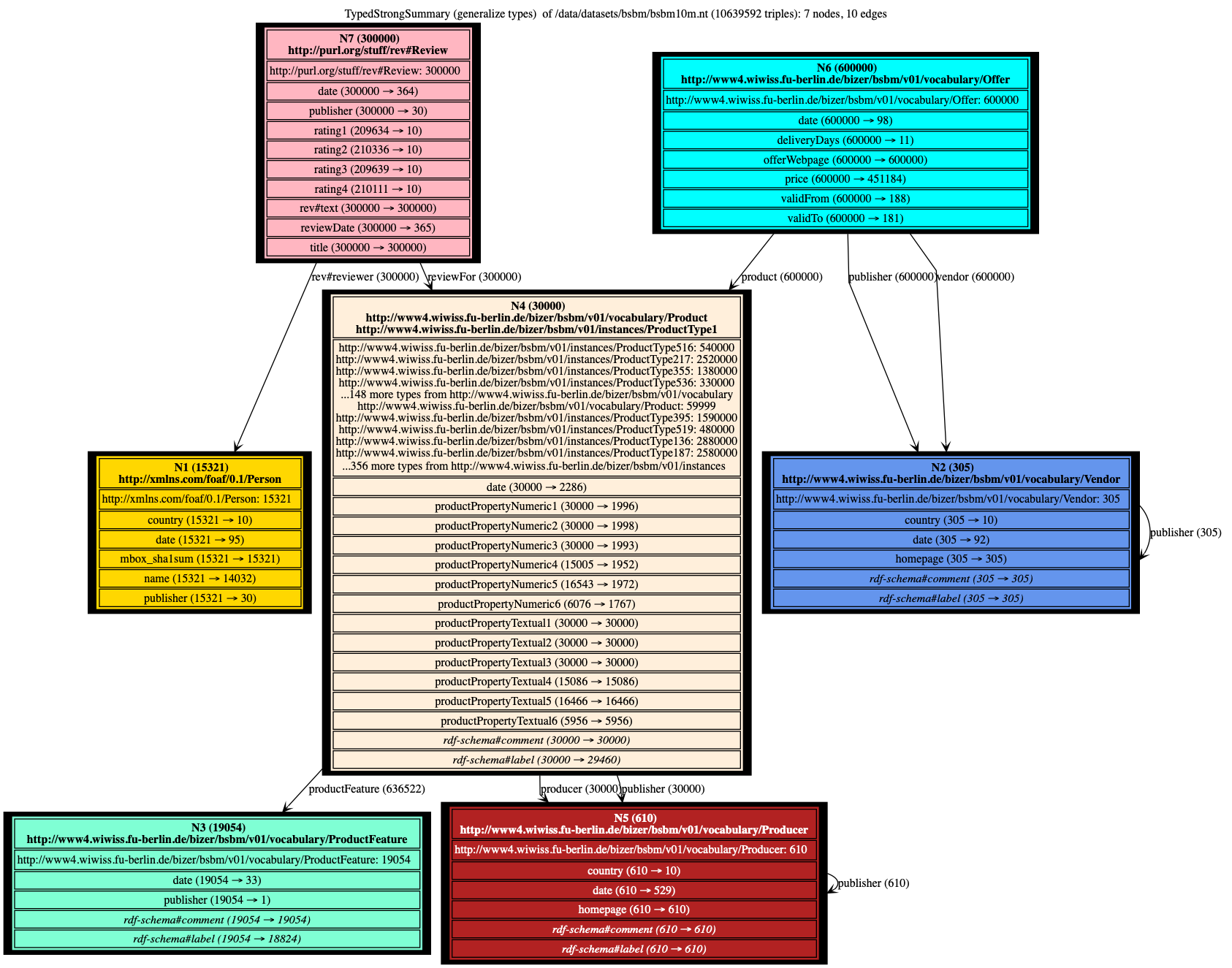
Below we show the Weak, Strong, Typed Weak and Typed Strong summaries of a 10 million triples BSBM benchmark graph (not saturated). BSBM models data about products which are for sale from different vendors; products are characterized by product features, and they have reviews, written by reviewers. In the BSBM benchmark scenario, products, reviews (and with them, the reviewers) are published by (originate from) different rating sites; publisher information remains attached to these resources, to state where they come from.

The Weak summary collapses all nodes into one. Many nodes are considered equivalent because they have the outgoing property publisher, which, in turn, makes other (quite unrelated) properties equivalent (part of the same source clique).
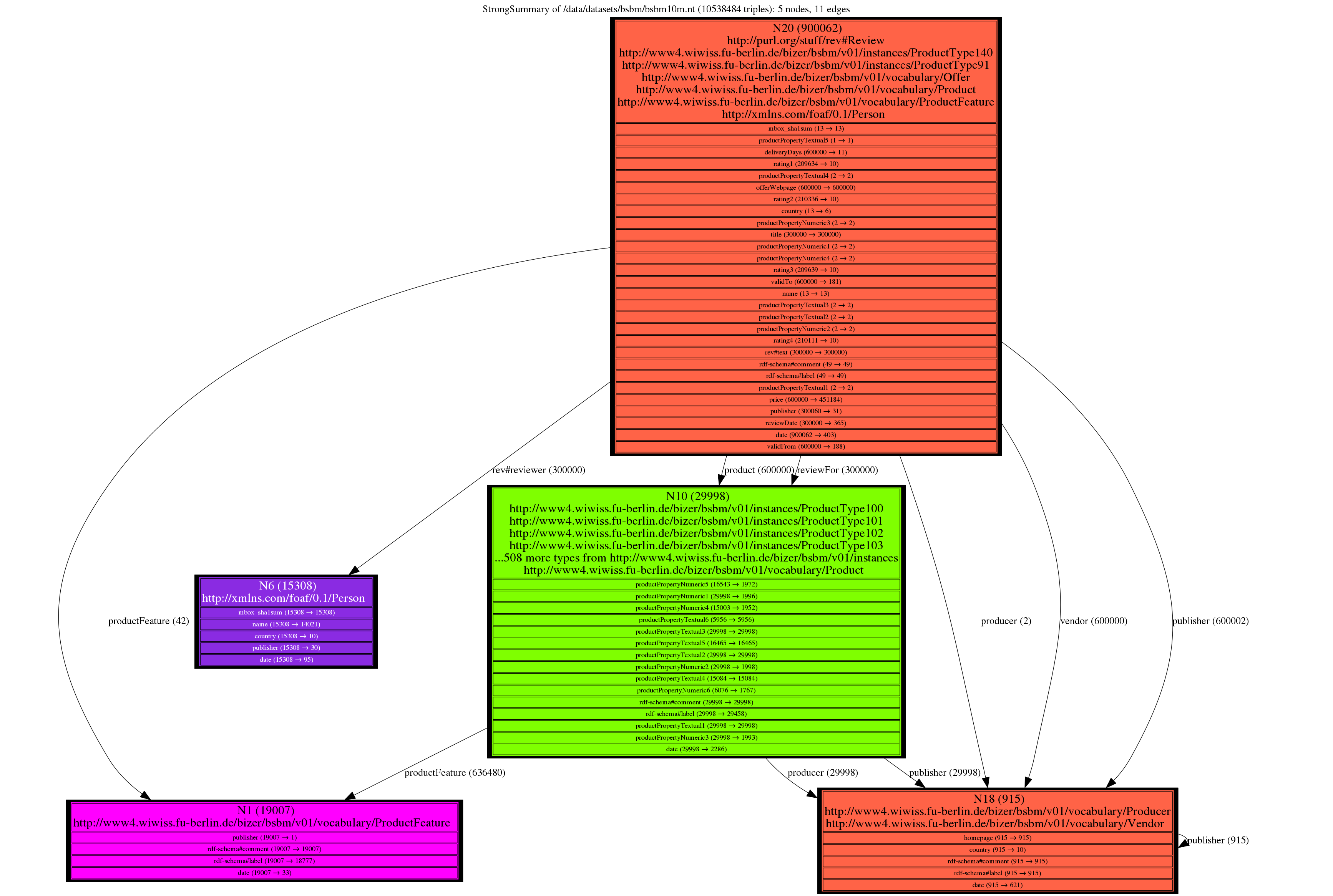
The Strong summary achieves a much more readable separation. The central node and the upper node mostly represent products. The upper node also represents Offers and Reviews; the central node only represents Products. Strong summarization sets them apart because Offers and Reviews (upper node) refer to products (lower node). Thus, BSBM graph nodes represented by these two nodes are separated into the sources (top) and targets (center) of the edges labeled “product” (connecting Offers to the Product) and “reviewFor” (connecting Reviews to the Products they are about).
The small node at the left represents the people who wrote product reviews; the node at the bottom groups vendors and producers, which are those that produced and published product information; the node at the bottom right represents all the product features.
Our TypedWeak, TypedStrong summaries can only be meaningful thanks to our technique of finding the most general types. Summarizing by giving priority to types, without generalizing them, leads to huge numbers of nodes and edges; the summary cannot be rendered nor is it comprehensible for humans.
Summaries based on bisimulation had even more nodes and edges; they cannot be meaningfully rendered in the same way.